
[기획-재난 없는 국가] 12. 화재 탐지 영역의 이미지와 동영상 인식 사이 인공지능 모델 성능 비교 연구
동영상 기반의 딥러닝 모델이 정확한 화재탐지에 더 적절하다는 것을 실험으로 증명... YOLO는 배경의 영향을 많이 받아 주변이 너무 밝거나 흐리면 탐지 성능이 급감
2025-04-08

최근 경상북도와 경상남도에서 대규모 산불이 발생해 엄청난 피해가 발생했다. 험준한 산악 지형과 건조한 날씨는 화재 진압 자체를 불가능하게 만들었다.
군인을 포함한 대규모 인력을 동원하고 군용 헬기까지 투입하고서야 진화가 가능해졌다. 화재를 사전에 예방하고 초기에 발견하는 것이 중요하다는 사실을 새삼 일깨워준 사건이었다.
중앙대 ICT융합안전 전공자인 이정록, 이대웅, 정서현 등이 쓴 '화재 탐지 영역의 이미지와 동영상 인식 사이 인공지능 모델 성능 비교 연구(A Comparative Study on Artificial in Intelligence Model Performance between Image and Video Recognition in the Fire Detection Area)라는 논문을 소개한다.
군인을 포함한 대규모 인력을 동원하고 군용 헬기까지 투입하고서야 진화가 가능해졌다. 화재를 사전에 예방하고 초기에 발견하는 것이 중요하다는 사실을 새삼 일깨워준 사건이었다.
중앙대 ICT융합안전 전공자인 이정록, 이대웅, 정서현 등이 쓴 '화재 탐지 영역의 이미지와 동영상 인식 사이 인공지능 모델 성능 비교 연구(A Comparative Study on Artificial in Intelligence Model Performance between Image and Video Recognition in the Fire Detection Area)라는 논문을 소개한다.
◇ 오탐지율을 낮추기 위해 화재 상황 분류 모델과 학습데이터셋 제안
최근 기후재난 이슈와 더불어 캐나다 산불, 하와이 산불과 같은 화재로 인해 엄청난 재산과 인명피해가 발생하고 있다. 화재를 예방하기 위한 노력과 함께 피해를 최대한 줄일 수 있게 화재를 조기에 탐지하기 위한 연구가 진행되고 있다.
현재 소방 분야에서는 화재를 탐지하기 위한 불꽃, 연기, 가스 등을 감지하는 센서를 설치해 관리하고 있다. 센서를 활용한 방식은 가격이 저렴하고 작동이 편리해 건물 및 공장 등에 많이 설치돼 있다.
하지만 정확도가 낮아 오탐이 많다. 이를 보완하기 위해 딥러닝 인공지능 기술인 CNN, Transformer 등의 신경망을 이용한 화재 탐지 모델에 대한 연구가 활발하다.
불꽃 및 연기 객체를 탐지하는 화재 탐지 모델은 입력 영상에서 클래스 정의한 객체의 특징을 추출해 인식하는 기술로 실시간성을 확보하기 위해 모델을 경량화하는 쪽으로 연구가 계속되고 있다.
여러 폐쇄회로TV(CCTV) 영상을 동시에 분석할 수 있게 경량화된 모델은 CCTV 기반 화재 탐지 시스템에 적용되고 적은 비용으로 많은 공간을 넓게 모니터링할 수 있다. 그러나 경량화로 인해 오탐지율이 높아 이를 개선하기 위한 연구가 활발하다.
오탐지율을 낮추기 위해 화재 상황 분류 모델과 학습데이터셋을 제안한다. 기존 탐지 모델과 학습방법에 대해 실험을 통해 비교, 평가해 제안방법의 우수성을 증명한다.
◇ 동영상 기반의 딥러닝 모델이 정확한 화재탐지에 더 적절하다는 것을 실험으로 증명
딥러닝 기술을 기반으로 한 객체 탐지 기술은, 연산 속도를 비약적으로 단축한 YOLO 모델이 2015년 처음 발표되면서부터 실시간 탐지 프로그램에 적용되기 시작했다.
초창기에는 연산 시간을 단축하는 것에 치중한 나머지 예측 성능이 떨어진다는 평가를 받기도 했지만 2023년을 기준으로 8번째 버전까지 고도화를 거치면서 정확도와 실용성을 모두 갖춘 기술로 평가받고 있다. 하지만 불꽃과 연기를 탐지하도록 훈련된 모델은 실제 화재를 감지할 때 사용하기 어려운 성능 수준을 보인다.
이는 객체 탐지 모델은 탐지하고자 하는 객체의 형태가 명확할수록 성능이 올라가지만 화재에서 발생하는 불꽃과 연기는 시각적인 경계가 모호하고,객체의 크기와 형태 또한 다양한 양상을 보이기 때문이다.
이러한 특징은 학습데이터를 구축할 때도 일관된 레이블링 작업을 어렵게 만들기 때문에 모델의 성능이 더욱 떨어지는 원인이 된다.
예를 들면 길쭉하게 뻗어 퍼지고 있는 연기의 경우, 직사각형 모양으로 해당 객체를 표시했을 때 연기를 포함하는 영역보다 포함하지 않는 영역이 더욱 커질 수 있어 모델의 성능을 저하하는 원인이 된다.
이러한 객체 탐지 모델의 한계점을 극복하기 위해 기존 YOLO 모델에 optical flow 같은 광학적 특성들을 전처리 과정을 통해 모델에 입력하거나 다양한 크기의 불꽃을 학습하기 위해 모델 구조에 변화를 주는 방식을 시도하고 있다.
하지만 복잡한 전처리가 필요하거나 연산 속도가 느려지는 등의 한계가 존재한다. 따라서 기존 이미지 데이터를 사용한 방식보다는 여러 프레임을 한번에 고려하는 동영상 기반의 딥러닝 모델이 정확한 화재탐지에 더 적절하다는 것을 실험으로 증명하려 한다.
◇ Kinetics-400 데이터를 사전 훈련한 모델에 NIA 화재 데이터셋 추가 학습
이미지 기반 모델은 실시간 탐지 프로그램에 적용할 수 있으며, 2023년을 기준으로 8번째 버전까지 고도화를 거쳐 정확도와 실용성을 모두 갖춘 YOLOv8 모델을 선정했다.
COCO(Microsoft Common Objects in Context) 데이터를 사전 훈련한 모델에 대해 NIA 화재 데이터셋을 추가 학습했다. 아래 그림은 YOLO 모델 구조를 보여준다.
동영상 기반 모델은 공간과 시간 축의 프레임 수를 달리해 빠르게 변화하는 모션을 인지하는 네트워크와 느리게 변화하는 모션을 인지하는 네트워크로 구분하는 SlowFast 모델을 선정했다. Kinetics-400 데이터를 사전 훈련한 모델에 NIA 화재 데이터셋을 추가 학습했다.
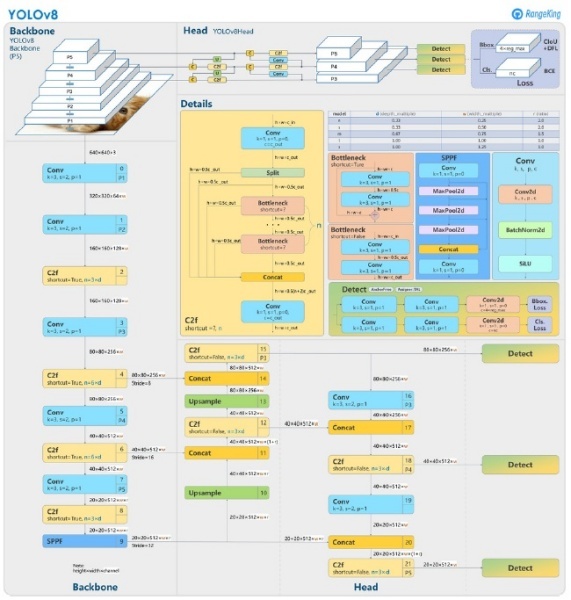
▲ YOLOv8 frame(locher, 2023)
◇ 한국정보화진흥원(NIA)에서 제공하는 데이터셋 사용
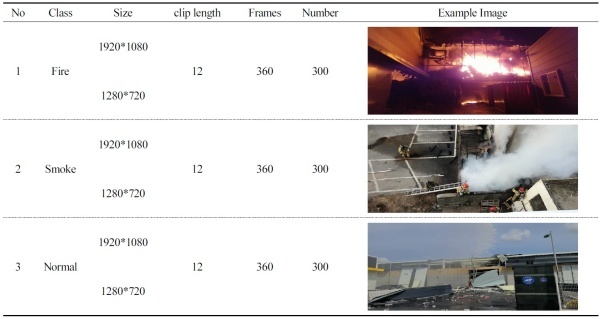
데이터는 한국정보화진흥원(NIA)에서 제공하는 데이터셋을 사용했으며 데이터는 1920x1080과 1280x720 크기로 12초 길이의 30FPS 클립으로 구성돼 있다.
클래스는 “정상(NONE)”, “연기(SMOKE)”, “불꽃(FLAME)” 3개로 구분했다. 영상에는 불꽃과 연기 등이 다양하게 분포돼 있다. 이미지 기반 모델 동영상 데이터를 이미지로 변환해 학습을 진행한다.
이 때 정상은 학습할 수 없기 때문에 연기와 불꽃 탐지만 할 수 있도록 학습을 진행하며 이후 후처리를 통해 정상 클래스를 분류한다.
각 불꽃, 연기, 정상은 300개 클립으로 Table 1과 같이 구성했고 Table 2는 학습, 검증, 테스트가 8:1:1 비율로 구성됨을 보여준다.
▲ Data for each class, 1:1:1 composition of proportions
◇ 성능 평가... 이미지와 동영상 기반 모델을 동일한 조건으로 평가
평가는 동영상 데이터에 대해 정상, 연기, 불꽃 클래스를 올바르게 분류했는지를 P(Precision), R(Recall), F(F1-Score)로 평가한다.
이미지와 동영상 기반 모델을 동일한 조건으로 평가하기 위해 YOLO는 후처리를 통해 분류 형식에 맞도록 반환값을 조정한다.
1개의 클립은 360장의 이미지로 이뤄진 데이터를 사용하고 있기 때문에 YOLO는 1개의 클립에 대해 총 360장 이미지를 읽어 각 이미지 별로 클래스를 탐지한다. 탐지된 우선순위는 불꽃 >= 연기 > 정상으로 판단한다.
불꽃이 발생하는 경우엔 필연적으로 연기가 같이 발생하기 때문에 하나의 이미지에서 연기와 불꽃을 모두 탐지한 경우는 불꽃에 더 높은 우선 순위를 부여한다.
360장 이미지에 대해 각 클래스를 탐지한 후 후처리를 위해 S_TH(Score_Threshold)를 0.1, 0.2, ..., 1.0으로 0.1 STEP씩 S_TH를 증가하며 360장 이미지에서 탐지된 불꽃, 연기 비율을 카운팅한다.
이때 카운팅 수량이 S_TH를 넘어서면 해당 클래스로 분류했다고 판단하고 S_TH를 넘기지 못하면 정상 클래스로 분류했다고 판단한다.

▲ YOLO Post-processing methods
◇ 성능 비교... YOLO를 사용한 경우가 동영상 기반의 SlowFast 모델보다 정확도가 높게 나타나
테스트셋은 불꽃, 연기, 정상 클래스별 각 30개의 클립을 사용한다. 제한된 테스트셋 기준에선 전반적으로 이미지 기반의 탐지모델인 YOLO를 사용한 경우가 동영상 기반의 SlowFast 모델보다 정확도가 높게 나타났다.
하지만 YOLO는 화재가 발생했는데 불꽃이 작아 연기 위주인 경우에는 불꽃을 제대로 탐지하지 못했다. 불꽃의 밝기로 그 주변까지 밝아져 불꽃 형상이 명확하게 보이지 않는 경우에도 1개의 불꽃을 여러 개로 탐지하는 등의 오탐이 존재했다.
SlowFast는 YOLO와 다르게 불꽃이 작고 연기 위주인 경우에도 불꽃을 잘 탐지했다. 불꽃의 빛 번짐으로 불꽃 형상이 명확하지 않더라도 올바르게 탐지함을 확인했다.
다만 정상 recall과 연기 precision을 보면 두 클래스 사이 오탐이 성능을 저하시킴을 볼 수 있고 이는 정상에 대한 특징이 명확하지 않아 정상 영상에 존재하는 희미한 구름 등이 연기로 오탐을 일으키는 것으로 유추된다. 정상 데이터를 불꽃, 연기보다 배로 확보해 정상,연기,불꽃 별 성능 추이를 확인해볼 필요가 있다.
마지막으로 두 모델 모두 화재를 올바르게 탐지하지만 현재 테스트 케이스는 명확한 정상, 연기, 불꽃으로 나누어졌기에 YOLO가 보다 우수한 성능을 가짐을 확인할 수 있다.
하지만 노이즈가 많은 데이터를 입력으로 넣은 경우에는 YOLO의 오탐지가 더 높음을 확인할 수 있다. 이는 너무 소량의 테스트 데이터를 사용했으믈 현재 성능을 그대로 받아들이기 어려운 점을 시사한다.

▲ If the shape of the flame is not clearly visible due to the strong flame (YOLO / SlowFast)
◇ YOLO는 배경의 영향을 많이 받아 주변이 너무 밝거나 흐리면 탐지 성능이 급감
화재탐지 분야에서 이미지 기반의 모델 YOLO와 동영상 기반의 모델 SlowFast 성능을 비교해 둘 중 어느 접근법이 화재탐지 분야에 더 유효한지 실험했다.
YOLO는 배경의 영향을 많이 받아 주변이 너무 밝거나 흐리면 탐지 성능이 급감하며 화재의 규모가 너무 크거나 작을 때에도 화재를 제대로 감지하지 못했다.
이는 객체 탐지를 위해 레이블링 할 때 주변이 밝거나 흐린 경우 불꽃이나 연기의 형상을 일관되게 잡을 수 없기 때문으로 보이며 이는 모델 학습 시 성능 저하가 더 가중된 것으로 판단된다.
동영상 기반 모델 SlowFast는 FastPath와 SlowPath를 이용해 빠르게 변화하는 모션과 느리게 변화하는 모션을 인지하는 네트워크를 구분해 학습한다.
동영상의 시간 축을 같이 학습하기 때문에 비정형 객체에 대해 주변이 흐리거나 밝아 형상을 명확하게 유추할 수 없는 상황에서도 우수하게 화재를 탐지하는 것을 확인했다.
다만 SlowFast는 불꽃을 잘 예측하지만 정상과 연기 사이 오탐하는 경우가 빈번하다. 이를 개선하기 위해 정상 데이터 분포를 연기, 불꽃 대비 2~5배 가량 증가시키며 연기, 불꽃 성능은 유지하되 정상인 경우의 오탐을 줄이는 등 모델 성능 고도화를 위한 연구가 필요하다.
최근 기후재난 이슈와 더불어 캐나다 산불, 하와이 산불과 같은 화재로 인해 엄청난 재산과 인명피해가 발생하고 있다. 화재를 예방하기 위한 노력과 함께 피해를 최대한 줄일 수 있게 화재를 조기에 탐지하기 위한 연구가 진행되고 있다.
현재 소방 분야에서는 화재를 탐지하기 위한 불꽃, 연기, 가스 등을 감지하는 센서를 설치해 관리하고 있다. 센서를 활용한 방식은 가격이 저렴하고 작동이 편리해 건물 및 공장 등에 많이 설치돼 있다.
하지만 정확도가 낮아 오탐이 많다. 이를 보완하기 위해 딥러닝 인공지능 기술인 CNN, Transformer 등의 신경망을 이용한 화재 탐지 모델에 대한 연구가 활발하다.
불꽃 및 연기 객체를 탐지하는 화재 탐지 모델은 입력 영상에서 클래스 정의한 객체의 특징을 추출해 인식하는 기술로 실시간성을 확보하기 위해 모델을 경량화하는 쪽으로 연구가 계속되고 있다.
여러 폐쇄회로TV(CCTV) 영상을 동시에 분석할 수 있게 경량화된 모델은 CCTV 기반 화재 탐지 시스템에 적용되고 적은 비용으로 많은 공간을 넓게 모니터링할 수 있다. 그러나 경량화로 인해 오탐지율이 높아 이를 개선하기 위한 연구가 활발하다.
오탐지율을 낮추기 위해 화재 상황 분류 모델과 학습데이터셋을 제안한다. 기존 탐지 모델과 학습방법에 대해 실험을 통해 비교, 평가해 제안방법의 우수성을 증명한다.
◇ 동영상 기반의 딥러닝 모델이 정확한 화재탐지에 더 적절하다는 것을 실험으로 증명
딥러닝 기술을 기반으로 한 객체 탐지 기술은, 연산 속도를 비약적으로 단축한 YOLO 모델이 2015년 처음 발표되면서부터 실시간 탐지 프로그램에 적용되기 시작했다.
초창기에는 연산 시간을 단축하는 것에 치중한 나머지 예측 성능이 떨어진다는 평가를 받기도 했지만 2023년을 기준으로 8번째 버전까지 고도화를 거치면서 정확도와 실용성을 모두 갖춘 기술로 평가받고 있다. 하지만 불꽃과 연기를 탐지하도록 훈련된 모델은 실제 화재를 감지할 때 사용하기 어려운 성능 수준을 보인다.
이는 객체 탐지 모델은 탐지하고자 하는 객체의 형태가 명확할수록 성능이 올라가지만 화재에서 발생하는 불꽃과 연기는 시각적인 경계가 모호하고,객체의 크기와 형태 또한 다양한 양상을 보이기 때문이다.
이러한 특징은 학습데이터를 구축할 때도 일관된 레이블링 작업을 어렵게 만들기 때문에 모델의 성능이 더욱 떨어지는 원인이 된다.
예를 들면 길쭉하게 뻗어 퍼지고 있는 연기의 경우, 직사각형 모양으로 해당 객체를 표시했을 때 연기를 포함하는 영역보다 포함하지 않는 영역이 더욱 커질 수 있어 모델의 성능을 저하하는 원인이 된다.
이러한 객체 탐지 모델의 한계점을 극복하기 위해 기존 YOLO 모델에 optical flow 같은 광학적 특성들을 전처리 과정을 통해 모델에 입력하거나 다양한 크기의 불꽃을 학습하기 위해 모델 구조에 변화를 주는 방식을 시도하고 있다.
하지만 복잡한 전처리가 필요하거나 연산 속도가 느려지는 등의 한계가 존재한다. 따라서 기존 이미지 데이터를 사용한 방식보다는 여러 프레임을 한번에 고려하는 동영상 기반의 딥러닝 모델이 정확한 화재탐지에 더 적절하다는 것을 실험으로 증명하려 한다.
◇ Kinetics-400 데이터를 사전 훈련한 모델에 NIA 화재 데이터셋 추가 학습
이미지 기반 모델은 실시간 탐지 프로그램에 적용할 수 있으며, 2023년을 기준으로 8번째 버전까지 고도화를 거쳐 정확도와 실용성을 모두 갖춘 YOLOv8 모델을 선정했다.
COCO(Microsoft Common Objects in Context) 데이터를 사전 훈련한 모델에 대해 NIA 화재 데이터셋을 추가 학습했다. 아래 그림은 YOLO 모델 구조를 보여준다.
동영상 기반 모델은 공간과 시간 축의 프레임 수를 달리해 빠르게 변화하는 모션을 인지하는 네트워크와 느리게 변화하는 모션을 인지하는 네트워크로 구분하는 SlowFast 모델을 선정했다. Kinetics-400 데이터를 사전 훈련한 모델에 NIA 화재 데이터셋을 추가 학습했다.
▲ YOLOv8 frame(locher, 2023)
◇ 한국정보화진흥원(NIA)에서 제공하는 데이터셋 사용
데이터는 한국정보화진흥원(NIA)에서 제공하는 데이터셋을 사용했으며 데이터는 1920x1080과 1280x720 크기로 12초 길이의 30FPS 클립으로 구성돼 있다.
클래스는 “정상(NONE)”, “연기(SMOKE)”, “불꽃(FLAME)” 3개로 구분했다. 영상에는 불꽃과 연기 등이 다양하게 분포돼 있다. 이미지 기반 모델 동영상 데이터를 이미지로 변환해 학습을 진행한다.
이 때 정상은 학습할 수 없기 때문에 연기와 불꽃 탐지만 할 수 있도록 학습을 진행하며 이후 후처리를 통해 정상 클래스를 분류한다.
각 불꽃, 연기, 정상은 300개 클립으로 Table 1과 같이 구성했고 Table 2는 학습, 검증, 테스트가 8:1:1 비율로 구성됨을 보여준다.
▲ Data for each class, 1:1:1 composition of proportions
◇ 성능 평가... 이미지와 동영상 기반 모델을 동일한 조건으로 평가
평가는 동영상 데이터에 대해 정상, 연기, 불꽃 클래스를 올바르게 분류했는지를 P(Precision), R(Recall), F(F1-Score)로 평가한다.
이미지와 동영상 기반 모델을 동일한 조건으로 평가하기 위해 YOLO는 후처리를 통해 분류 형식에 맞도록 반환값을 조정한다.
1개의 클립은 360장의 이미지로 이뤄진 데이터를 사용하고 있기 때문에 YOLO는 1개의 클립에 대해 총 360장 이미지를 읽어 각 이미지 별로 클래스를 탐지한다. 탐지된 우선순위는 불꽃 >= 연기 > 정상으로 판단한다.
불꽃이 발생하는 경우엔 필연적으로 연기가 같이 발생하기 때문에 하나의 이미지에서 연기와 불꽃을 모두 탐지한 경우는 불꽃에 더 높은 우선 순위를 부여한다.
360장 이미지에 대해 각 클래스를 탐지한 후 후처리를 위해 S_TH(Score_Threshold)를 0.1, 0.2, ..., 1.0으로 0.1 STEP씩 S_TH를 증가하며 360장 이미지에서 탐지된 불꽃, 연기 비율을 카운팅한다.
이때 카운팅 수량이 S_TH를 넘어서면 해당 클래스로 분류했다고 판단하고 S_TH를 넘기지 못하면 정상 클래스로 분류했다고 판단한다.
▲ YOLO Post-processing methods
◇ 성능 비교... YOLO를 사용한 경우가 동영상 기반의 SlowFast 모델보다 정확도가 높게 나타나
테스트셋은 불꽃, 연기, 정상 클래스별 각 30개의 클립을 사용한다. 제한된 테스트셋 기준에선 전반적으로 이미지 기반의 탐지모델인 YOLO를 사용한 경우가 동영상 기반의 SlowFast 모델보다 정확도가 높게 나타났다.
하지만 YOLO는 화재가 발생했는데 불꽃이 작아 연기 위주인 경우에는 불꽃을 제대로 탐지하지 못했다. 불꽃의 밝기로 그 주변까지 밝아져 불꽃 형상이 명확하게 보이지 않는 경우에도 1개의 불꽃을 여러 개로 탐지하는 등의 오탐이 존재했다.
SlowFast는 YOLO와 다르게 불꽃이 작고 연기 위주인 경우에도 불꽃을 잘 탐지했다. 불꽃의 빛 번짐으로 불꽃 형상이 명확하지 않더라도 올바르게 탐지함을 확인했다.
다만 정상 recall과 연기 precision을 보면 두 클래스 사이 오탐이 성능을 저하시킴을 볼 수 있고 이는 정상에 대한 특징이 명확하지 않아 정상 영상에 존재하는 희미한 구름 등이 연기로 오탐을 일으키는 것으로 유추된다. 정상 데이터를 불꽃, 연기보다 배로 확보해 정상,연기,불꽃 별 성능 추이를 확인해볼 필요가 있다.
마지막으로 두 모델 모두 화재를 올바르게 탐지하지만 현재 테스트 케이스는 명확한 정상, 연기, 불꽃으로 나누어졌기에 YOLO가 보다 우수한 성능을 가짐을 확인할 수 있다.
하지만 노이즈가 많은 데이터를 입력으로 넣은 경우에는 YOLO의 오탐지가 더 높음을 확인할 수 있다. 이는 너무 소량의 테스트 데이터를 사용했으믈 현재 성능을 그대로 받아들이기 어려운 점을 시사한다.
▲ If the shape of the flame is not clearly visible due to the strong flame (YOLO / SlowFast)
◇ YOLO는 배경의 영향을 많이 받아 주변이 너무 밝거나 흐리면 탐지 성능이 급감
화재탐지 분야에서 이미지 기반의 모델 YOLO와 동영상 기반의 모델 SlowFast 성능을 비교해 둘 중 어느 접근법이 화재탐지 분야에 더 유효한지 실험했다.
YOLO는 배경의 영향을 많이 받아 주변이 너무 밝거나 흐리면 탐지 성능이 급감하며 화재의 규모가 너무 크거나 작을 때에도 화재를 제대로 감지하지 못했다.
이는 객체 탐지를 위해 레이블링 할 때 주변이 밝거나 흐린 경우 불꽃이나 연기의 형상을 일관되게 잡을 수 없기 때문으로 보이며 이는 모델 학습 시 성능 저하가 더 가중된 것으로 판단된다.
동영상 기반 모델 SlowFast는 FastPath와 SlowPath를 이용해 빠르게 변화하는 모션과 느리게 변화하는 모션을 인지하는 네트워크를 구분해 학습한다.
동영상의 시간 축을 같이 학습하기 때문에 비정형 객체에 대해 주변이 흐리거나 밝아 형상을 명확하게 유추할 수 없는 상황에서도 우수하게 화재를 탐지하는 것을 확인했다.
다만 SlowFast는 불꽃을 잘 예측하지만 정상과 연기 사이 오탐하는 경우가 빈번하다. 이를 개선하기 위해 정상 데이터 분포를 연기, 불꽃 대비 2~5배 가량 증가시키며 연기, 불꽃 성능은 유지하되 정상인 경우의 오탐을 줄이는 등 모델 성능 고도화를 위한 연구가 필요하다.
 ▲ 정상 전문위원(중앙대학교 교수) |
저작권자 © 엠아이앤뉴스, 무단전재 및 재배포 금지



